Laya enriches your daily workflows with AI — whether you connect one platform or many. It researches context, drafts responses, and delivers ready-to-approve action cards before you even open the app — using local LLMs via Ollama and LM Studio, or your own API keys.
Open source. Local-first. Works with one platform or many. Your API keys, your data.

%22%20stroke%3D%22%23F5C242%22%20stroke-opacity%3D%220.5%22%2F%3E%0A%20%20%3Cg%20transform%3D%22translate(14%2C14)%22%3E%0A%20%20%20%20%3Crect%20width%3D%2252%22%20height%3D%2252%22%20rx%3D%2210%22%20fill%3D%22url(%23ring)%22%2F%3E%0A%20%20%20%20%3Ctext%20x%3D%2226%22%20y%3D%2236%22%20text-anchor%3D%22middle%22%20font-family%3D%22-apple-system%2CSegoe%20UI%2CRoboto%2Csans-serif%22%20font-size%3D%2226%22%20font-weight%3D%22800%22%20fill%3D%22%230F172A%22%3E%231%3C%2Ftext%3E%0A%20%20%3C%2Fg%3E%0A%20%20%3Cg%20transform%3D%22translate(80%2C22)%22%3E%0A%20%20%20%20%3Ctext%20font-family%3D%22-apple-system%2CSegoe%20UI%2CRoboto%2Csans-serif%22%20font-size%3D%229%22%20font-weight%3D%22700%22%20fill%3D%22%23FFD86B%22%20letter-spacing%3D%221.2%22%3E%231%20ON%20THE%20CAPITAL%3C%2Ftext%3E%0A%20%20%20%20%3Ctext%20y%3D%2218%22%20font-family%3D%22-apple-system%2CSegoe%20UI%2CRoboto%2Csans-serif%22%20font-size%3D%2213%22%20font-weight%3D%22700%22%20fill%3D%22%23F8FAFC%22%3E%231%20ai-automation-agent%3C%2Ftext%3E%0A%20%20%20%20%3Ctext%20y%3D%2234%22%20font-family%3D%22-apple-system%2CSegoe%20UI%2CRoboto%2Csans-serif%22%20font-size%3D%2210%22%20fill%3D%22%2394A3B8%22%3Eaitoolscapital.com%20%2F%20The%20Capital%3C%2Ftext%3E%0A%20%20%3C%2Fg%3E%0A%3C%2Fsvg%3E)
Laya is an open-source desktop app that brings your work tools — Gmail, Google Calendar, Slack, Jira, GitHub, and more — into one intelligent feed. When a new email, meeting invite, ticket, or pull request arrives, Laya's AI reads it, gathers related context from your connected tools, and turns it into an action card with a suggested response — drafted and ready for your review.
You stay in control: nothing is sent or changed on your behalf without your explicit approval. And because Laya is a desktop-only app with no servers behind it, your emails, events, and messages are stored entirely on your computer — and when you use a local model, they never leave your machine.
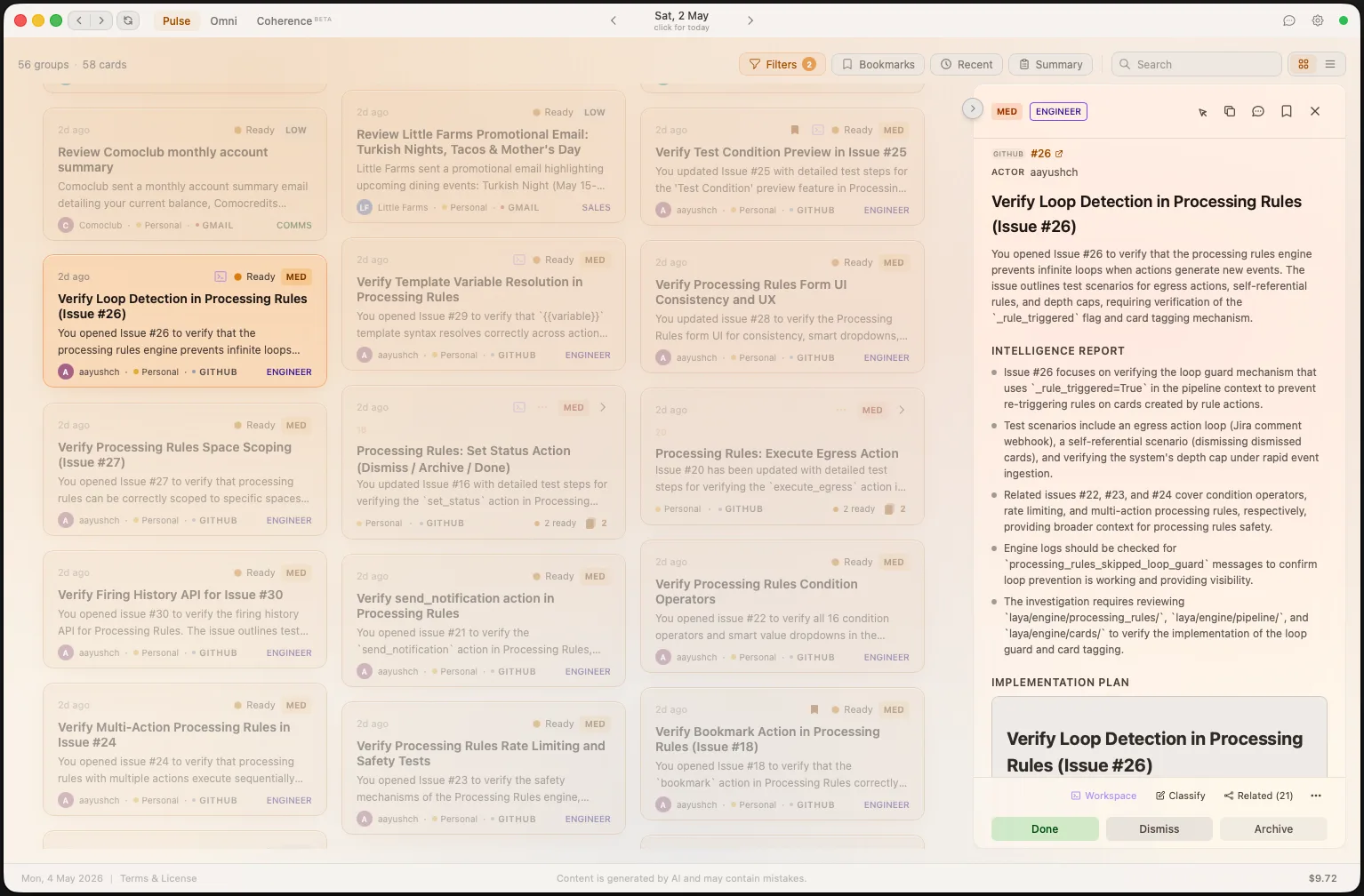
Whether you juggle eight tools or just an overflowing inbox — every notification demands attention and none of them come with context.
Every card Laya delivers has already been researched, classified, and prepared for action.
Every notification gets an AI-generated intelligence report. Sender reputation, cross-platform context, pattern recognition from your history, and actionable insights — all before you read a single word.
Draft replies, code fixes, briefing summaries — ready for one-click approval. The AI does the work. You just say "go" or refine the details.
Wake up to an AI-synthesized morning briefing. Events & meetings, action items, key updates — organized by priority across all your spaces.
Run coding agents (Claude Code, Gemini CLI, Codex, Pi CLI) directly from any card. Watch them work in real-time and guide their actions from the workspace.
Every event is automatically categorized by persona (Engineer, Comms, Ops, Finance, HR, Sales), priority (Critical to Low), and category — using a multi-model AI pipeline that learns from your corrections.
Organize your life into separate contexts — Work, Personal, side projects. Each space has its own sources, model configs, and API keys.
Search for any entity across all platforms and trace its full lifecycle — from Jira ticket to PR to Slack thread. Hybrid retrieval blends semantic vectors with keyword (BM25) ranking, and AI-generated narratives tell the complete story.
Execute outbound actions from a single interface — send emails, post Slack messages, comment on tickets, and more. AI-assisted drafting with full preview before sending.
Bookmark important cards for quick access. Filter your feed to show only bookmarked items — no matter the date or status.
A rolling cross-platform summary that answers "where am I right now?" at a glance. Four temporal layers — from items needing attention to long-term milestones — compressed by AI.
Automatically links related cards across platforms using semantic similarity and LLM confirmation. Learns editable grouping rules from your link/unlink corrections to improve accuracy over time.
Launch a fully configured agent session from any card. Choose your runtime, set an execution mode, configure directories, and write detailed prompts — with Plan or Accept Edits modes for full control.
Monitor LLM costs broken down by feature (Pulse, Omni, Chat, Coherence) and pipeline step. Set monthly spending caps with automatic pause when limits are reached.
Point any pipeline stage at an installed CLI agent — Claude Code, Codex, Gemini, or Pi — and Laya runs on that agent's own quota instead of a separate API key. A window-based usage budget auto-pauses ingestion before you hit a limit and resumes when the window resets.
Filter noise, auto-classify, and fire automated actions — tag, route, run an agent, send a reply — with optional AI-evaluated conditions. Every firing lands in a searchable log so you can see exactly what ran and why. Edit any rule straight from chat.
Works with cloud SaaS and on-prem instances alike — point a repo at Bitbucket Server / Data Center or GitHub Enterprise via a per-repo host, and Laya routes ingestion and outbound actions to the right place.
A multi-stage AI pipeline transforms raw notifications into ready-to-approve intelligence.
Events flow in from Gmail, Slack, Jira, GitHub, Calendar — connect as many or as few as you need.
Fast AI classifies priority, category, persona, and builds a research plan.
Specialized workers research context, draft replies, spawn coding agents, gather intelligence.
Polished action cards land in your feed with intelligence reports and one-click actions.
Laya doesn't just forward notifications. It investigates them. Each card includes an AI intelligence report with cross-platform context and pattern-matched history.
Switch between list view for rapid triage or card view for visual scanning. Sort by newest, priority, category, or platform. Context-grouped cards cluster related items automatically.
Every morning, Laya synthesizes overnight activity across all your platforms into a structured briefing. Events, action items, and key updates — prioritized and ready.
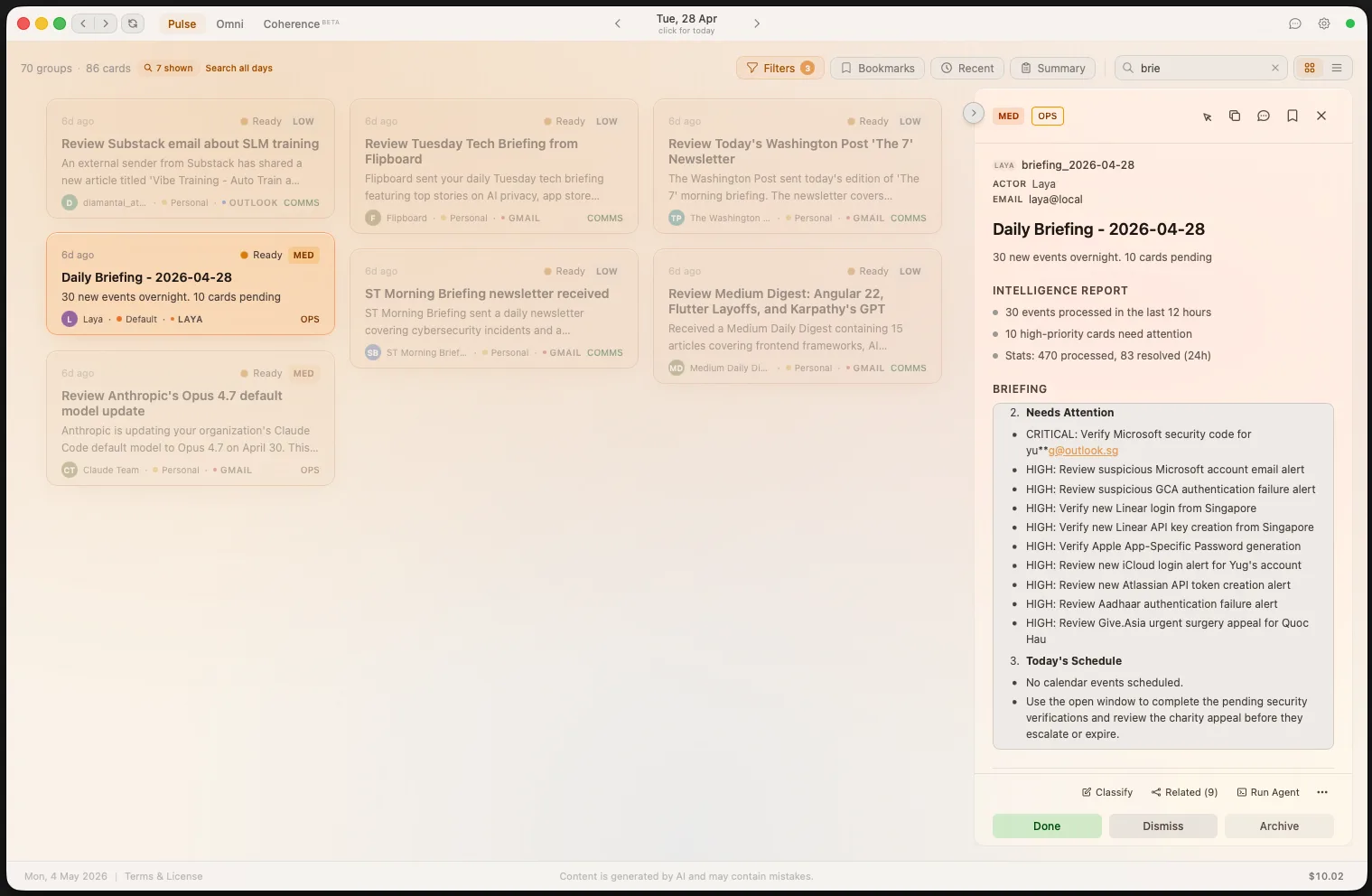
The Day Summary distills your entire day into a single structured view. Action items with pending counts, key updates filtered from noise, and space-level breakdowns — all generated and updated automatically.
Run coding agents — Claude Code, Gemini CLI, or Codex — directly from any card in your feed. Each session gets a dedicated workspace with a live timeline, context panel, and generated files.
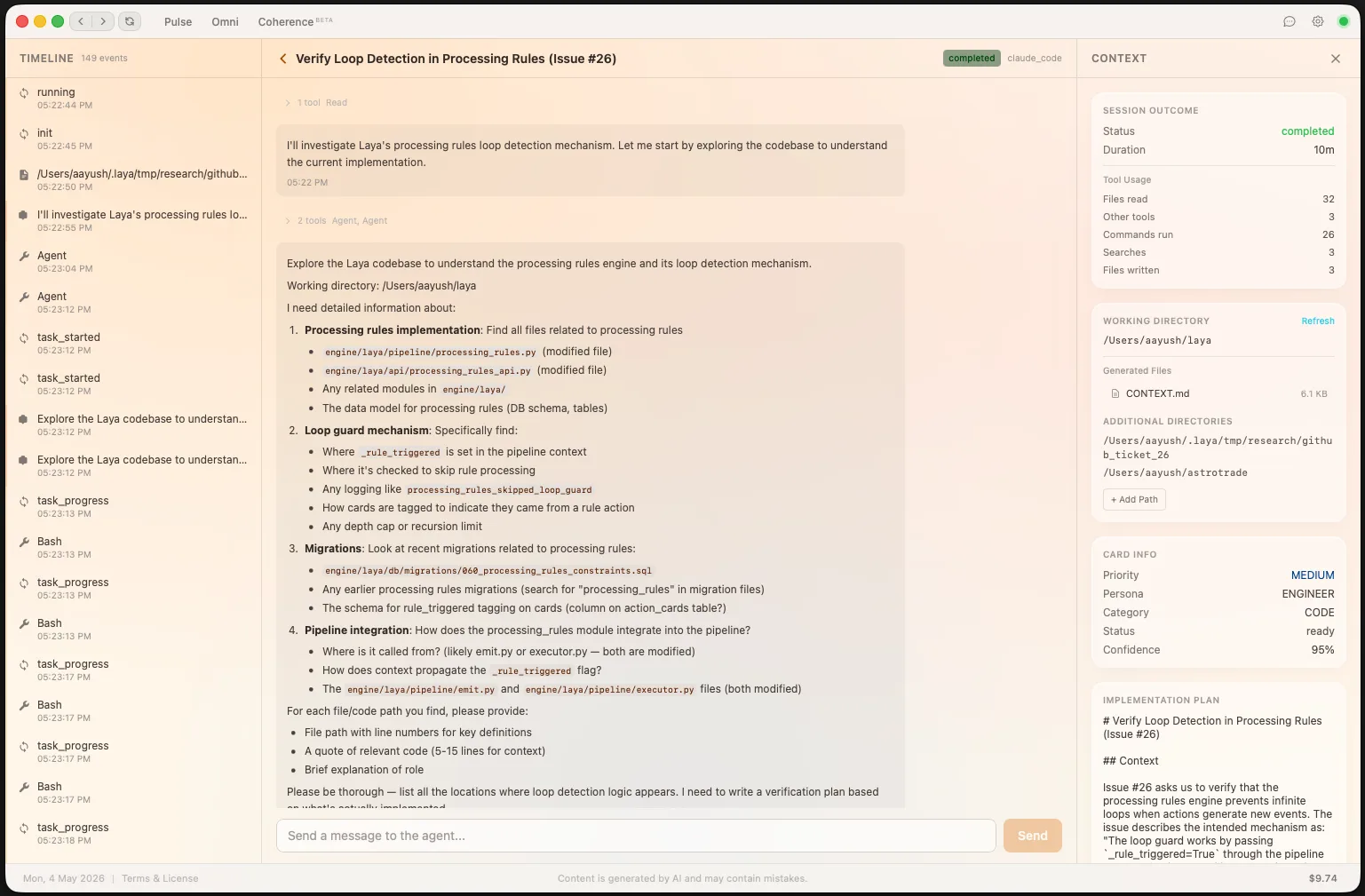
Laya's built-in chat uses hybrid semantic + keyword search across all your ingested events. Ask natural language questions and get instant, context-rich answers — with links back to the original cards and events.
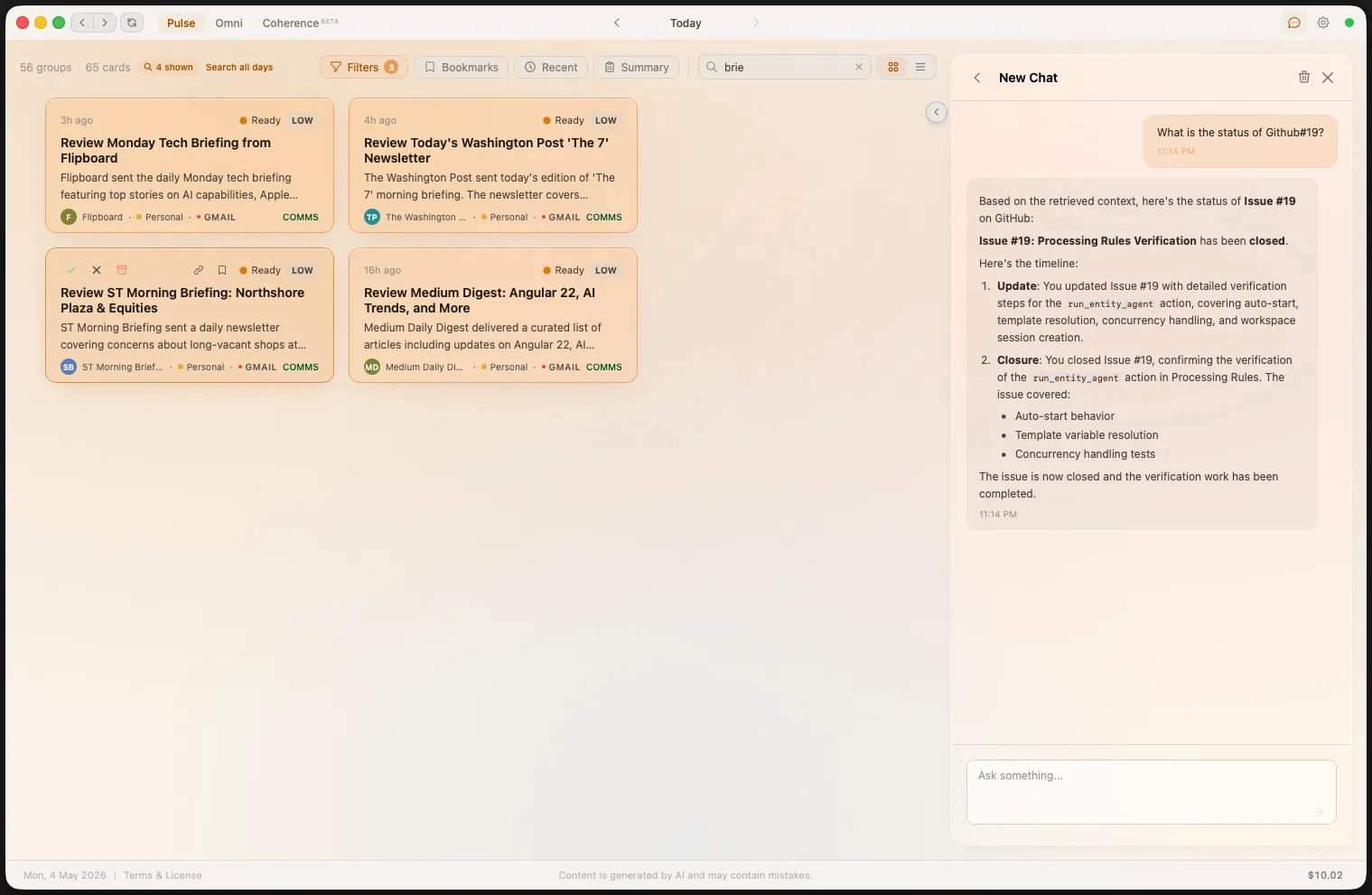
Omni is a rolling cross-platform summary that synthesizes all your professional activity into a single unified view. It answers "where am I right now?" — especially powerful after time away or for sprint retrospectives.
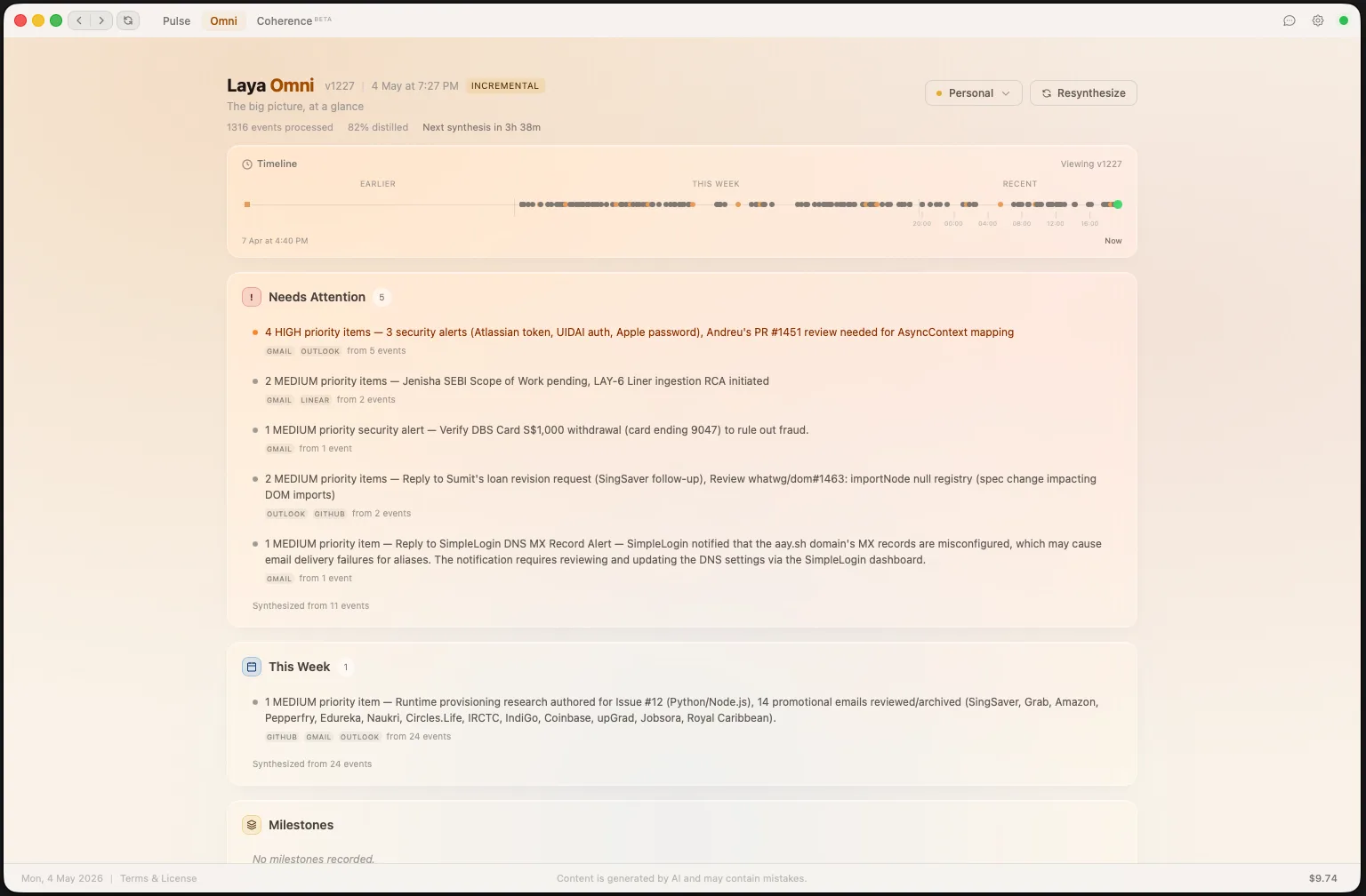
Coherence is Laya's cross-platform entity search. Search for a person, ticket, PR, or project and see its complete lifecycle — every event, every platform, one chronological story.
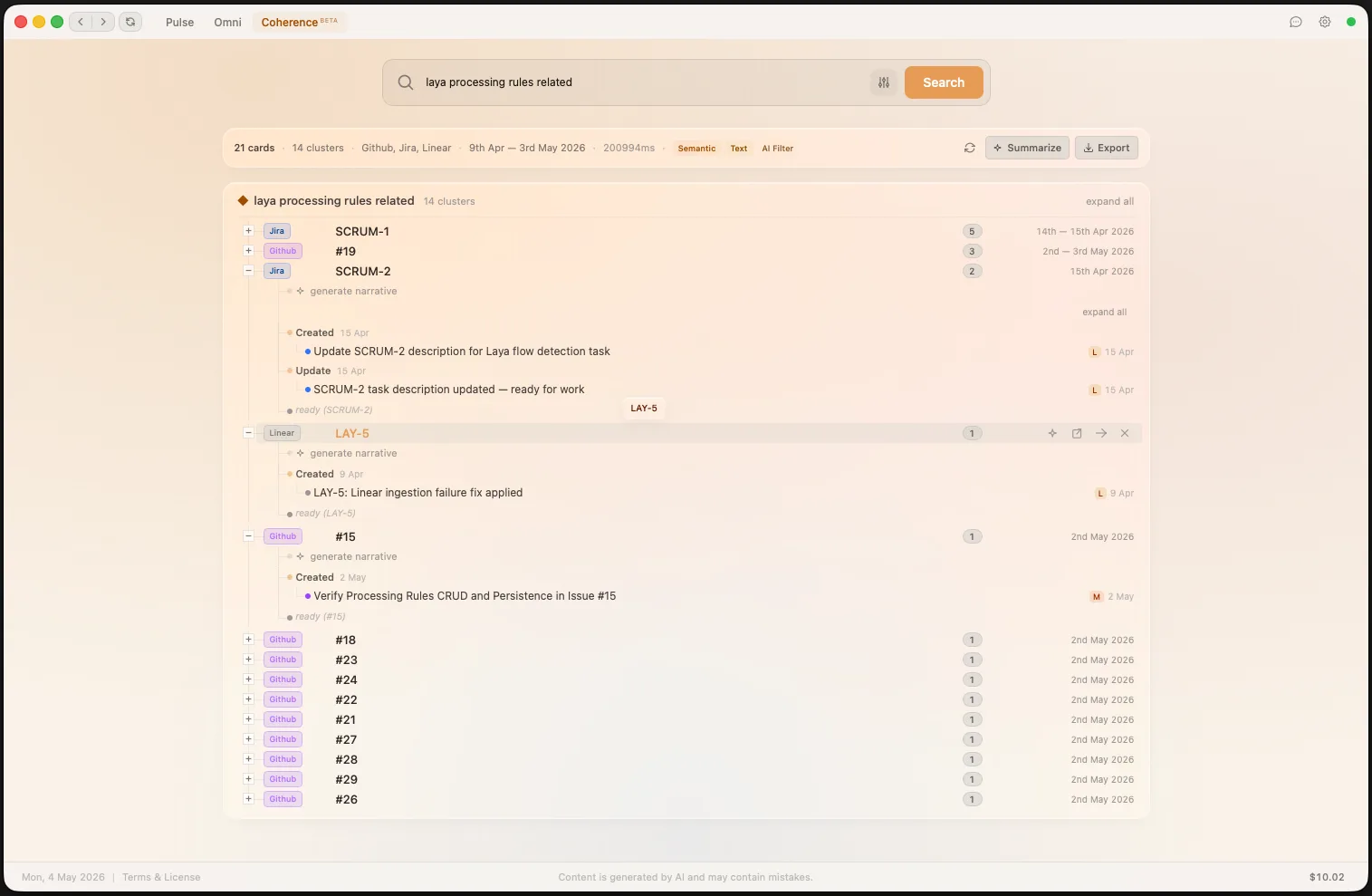
Laya's context association engine uses semantic similarity and LLM confirmation to automatically group cards that belong to the same real-world context — even across different platforms and entity types. Link or unlink groups manually, and Laya learns from every correction.
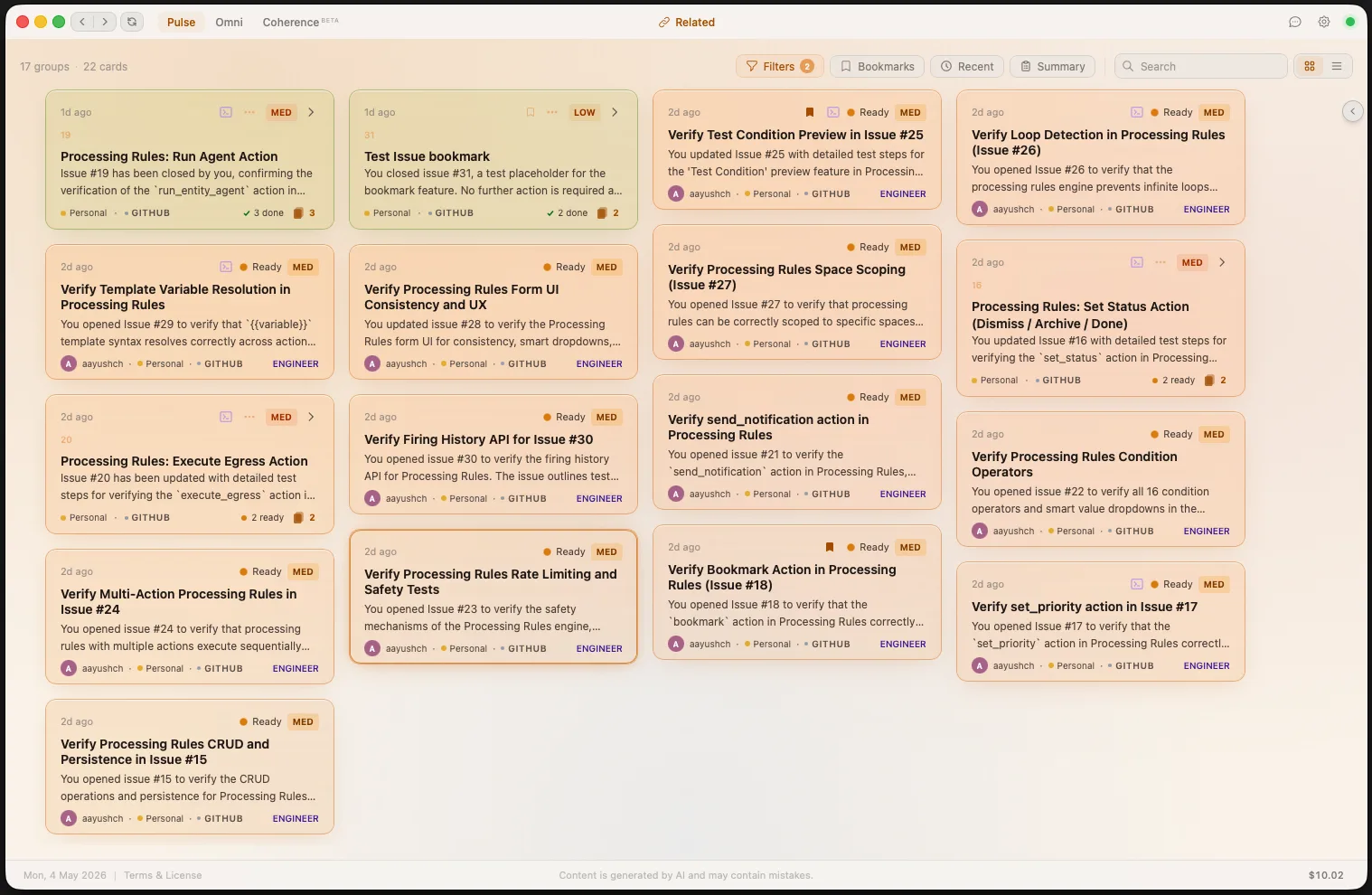
Every card in your feed has a Run Agent action. Provide an optional focus prompt and start the agent instantly — no context switching, no setup. The card's intelligence report and related entities are automatically injected as context.
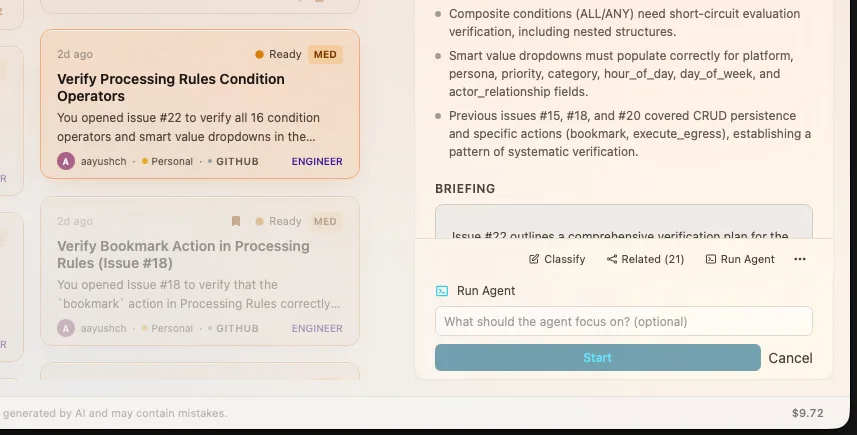
For complex tasks, the Agent Studio gives you full control. Choose your agent runtime, select an execution mode, configure working directories, attach reference files, and write detailed prompts — all before the agent starts.
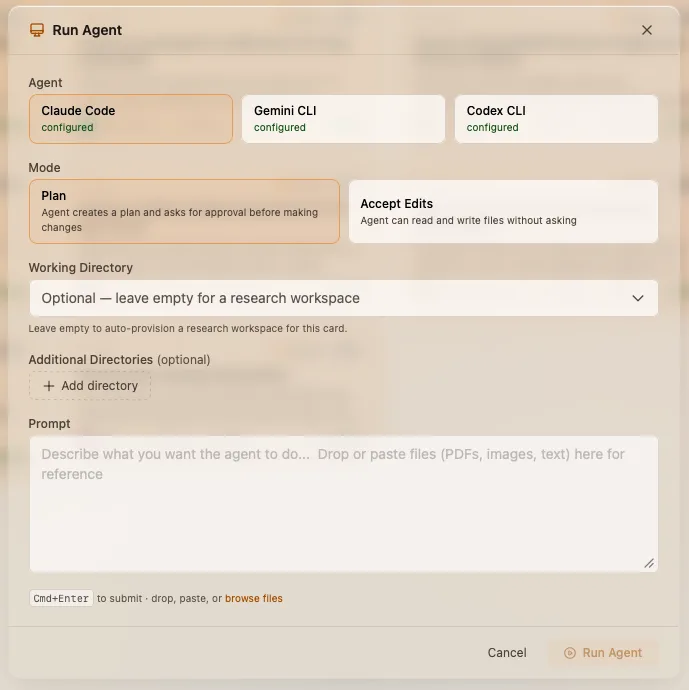
The Composer lets you execute actions across all connected platforms from a single modal. Send emails, post Slack messages, comment on Jira tickets, create GitHub issues, and more — with AI-assisted drafting and full preview before sending.
Laya's pipeline runs through distinct LLM stages — router, stager, the six persona workers, briefings,
summaries, semantic chat, and more. Drop a markdown file into ~/.laya/prompts/
for any stage and Laya uses your prompt instead of the default. No fork, no rebuild.
├─ router.md # classification ├─ stager.md # action drafting ├─ engineer.md # persona voice ├─ comms.md ├─ briefing.md # daily digest ├─ omni.md # rolling summary └─ … 16 more
Whenever Laya is running, a Model Context Protocol server is reachable at http://127.0.0.1:8420/mcp/.
Grab a token from Settings → MCP and wire any MCP-compatible client — Claude Desktop, Cursor, VS Code,
custom agents — straight into your live data.
{ "mcpServers": { "laya": { "command": "npx", "args": [ "mcp-remote", "http://127.0.0.1:8420/mcp/", "--allow-http", "--header", "Authorization: Bearer lyat_…" ] } } }
Laya automatically routes each notification to the right specialist persona, so you get expert-level output every time.
Spawns coding agents, analyzes PRs, reviews build failures, drafts code fixes, and surfaces implementation plans with full repo context.
Drafts email replies, Slack responses, and PR comments. Analyzes sender intent, checks communication history, and prepares context-aware responses.
Aggregates calendar events, manages scheduling conflicts, synthesizes meeting prep, and monitors operational updates across all platforms.
Processes invoices, expense reports, and budget updates. Flags financial anomalies and prepares cost summaries across your accounts.
Handles people-related events — onboarding, leave requests, team announcements, and HR policy updates. Recognizes internal people operations.
Tracks prospects, deals, and pipeline activity. Summarizes customer interactions and flags deal-stage changes that need attention.
Connect one tool or all of them. Laya normalizes everything into a unified, AI-enriched event stream.
Laya is local-first by design. Your data never leaves your machine unless you choose a cloud model.
SQLite database, ChromaDB vectors, and all configs stored on your machine. No cloud account required.
Bring your own API keys. Use Claude, GPT, Gemini, or run Ollama locally for complete air-gapped privacy.
Sensitive content (DMs, emails) can be routed to local models only. Metadata stays separate from content.
Laya is free and open source. Connect your first tool, run the engine, and let AI handle the rest.